AI-generated summary
Paperlib is a free, open-source, and minimalist academic paper management tool developed by GeoffreyChen, primarily aimed at the computer science discipline. In this article, I’d like to share my experiences using literature management tools and explain why I recommend Paperlib here.
Introduction
Whether in the open-source community or the application market, tools for document management have matured considerably. There are longstanding options like EndNotes, which many universities prefer to purchase. Then there are free options like Mendely and Zotero. Additionally, there’s a software I used to like called ReadCube Papers, formerly known as Papers, which initially offered services through a one-time purchase on the App Store before being acquired by ReadCube and transitioning to a yearly subscription model priced at $24 annually (with student discounts). Also, there’s ReadPaper, developed by students from the Greater Bay Area Digital Economy Research Institute, which has gained significant traction recently.
Ultimately, the choice of tool largely depends on individual preferences. The tool we’ll discuss today, Paperlib, partly reflects my own preferences. Paperlib is open-source on GitHub, developed and maintained solely by its author, who currently provides support for Windows, Linux, and macOS.
What caught my eye about this tool is its user interface – simple yet feature-rich. There’s no learning curve; you can easily manage your papers with it. Moreover, since the developer is also a computer science student who initially aimed at organizing papers in the computer science field, I found it particularly intuitive to use.
I’m a computer science PhD student. Conference papers are in major in my research community, which is different from other disciplines. Without DOI, ISBN, metadata of a lot of conference papers are hard to look up (e.g., NIPS, ICLR etc.). When I cite a publication in a draft paper, I need to manually search the publication information of it in Google Scholar or DBLP over and over again.
Why not Zotero, Mendely?
- A good metadata scraping capability is one of the core functions of a paper management tool. Unfortunately, no software in this world does this well, not even commercial software.
- A modern UI. No extra useless features.
What we need may be to: import a paper, scrape the metadata of it as accurately as possible, simply organise the library, and export it to BibTex when we are writing our papers.
That is Paperlib.
— From the Paperlib official website introduction
My Expectations for Paper Management Tools
Organization and Management: I expect my papers to be organized neatly in a visually pleasing table, with adequate row height and width to ensure sufficient information while providing an enjoyable experience. Additionally, the tool should offer various viewing options, filtering, and sorting capabilities, along with robust search functionality including full-text search, title search, or custom search. Furthermore, it should support paper categorization with features like different folders, nested folders, tag support, and intelligent paper classification, all visible as soon as I open the tool. Adding papers should be convenient, with options such as browser extensions and direct dragging of papers.
Preview and Reading: It should allow quick opening of papers for viewing within the management tool and enable me to save my own notes after reading papers for summarization. Ideally, the management tool should provide a smooth PDF experience similar to PDF Expert.
Discovering New Papers: It would be beneficial if the tool could recommend the latest papers that might be helpful based on the papers in my library.
Multi-Platform Sync: My papers should be stored within the tool and synchronized across multiple platforms, allowing operations on mobile, desktop, and web versions at any time.
Information and Citation: I should be able to quickly obtain the Bibtex information of papers for importing into LaTeX or Word for writing papers. Additionally, a good document management tool should include a wealth of information about each paper, including citation metrics such as citation count, and ideally, provide links to corresponding GitHub projects or other relevant resources.
How Paperlib Achieves This
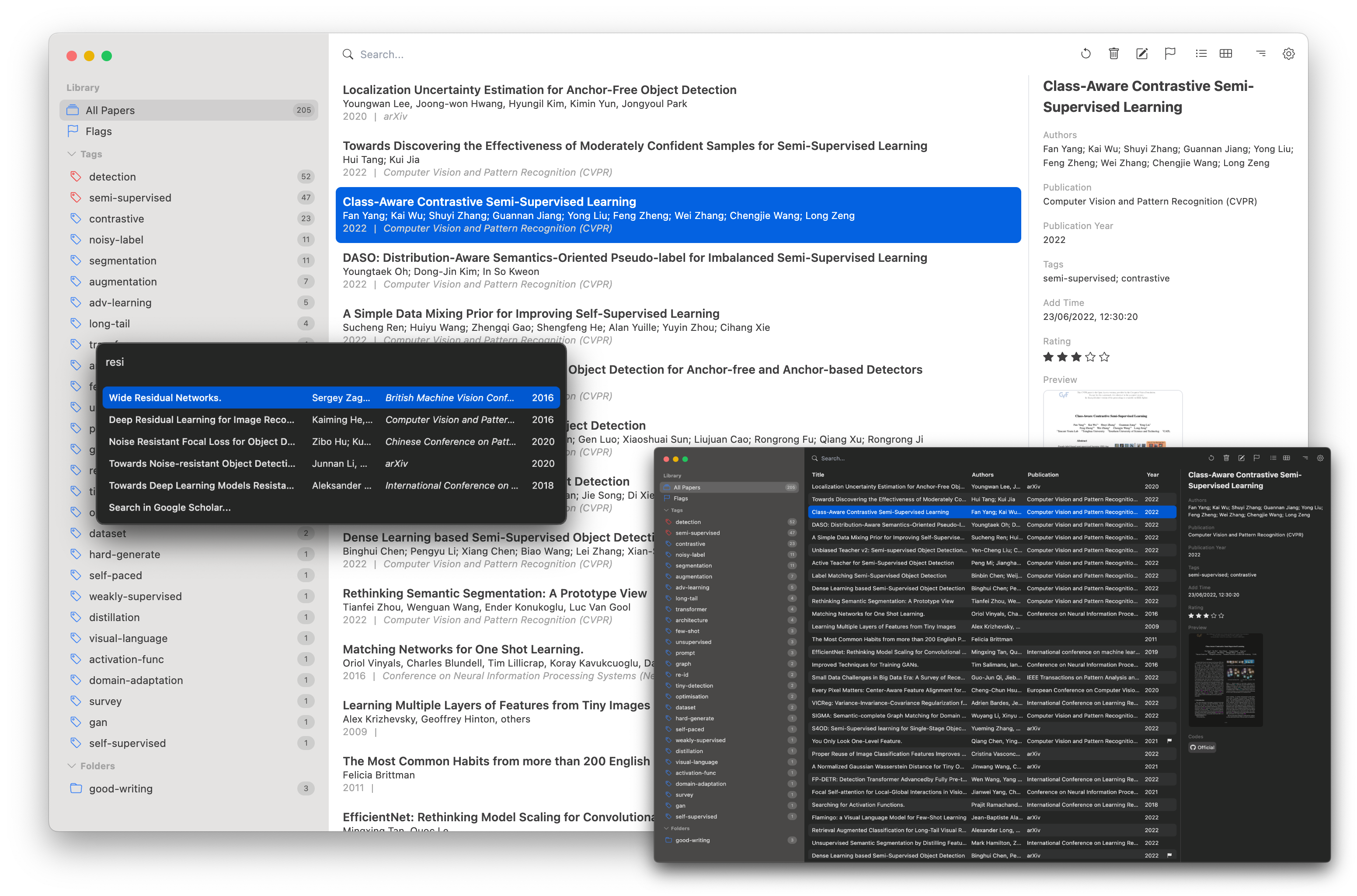
As a document management tool, Paperlib boasts a refreshingly simple interface that gives me a sense of balance, both visually and in terms of usability. There’s no clutter; when you open it, you’re immediately taken to the main page displaying your papers. It doesn’t require you to log in or bother you with account-related prompts, which is one of the aspects I like most about it. Utilizing the Electron framework ensures a consistent interface across the three desktop platforms. Its most powerful feature is the extraction of paper metadata. We can customize various sources for fetching paper data and likewise for downloading papers; you can choose to use tools like arXiv, SemanticScholar, or X-Hub to help you obtain PDF files of papers.
Organization and Management
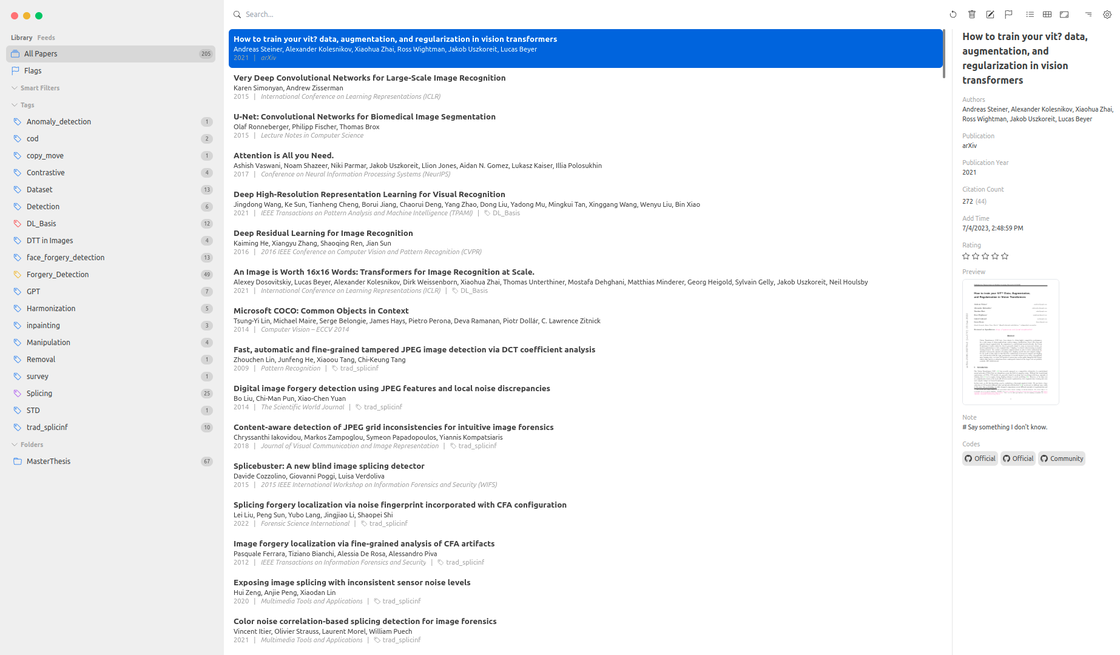
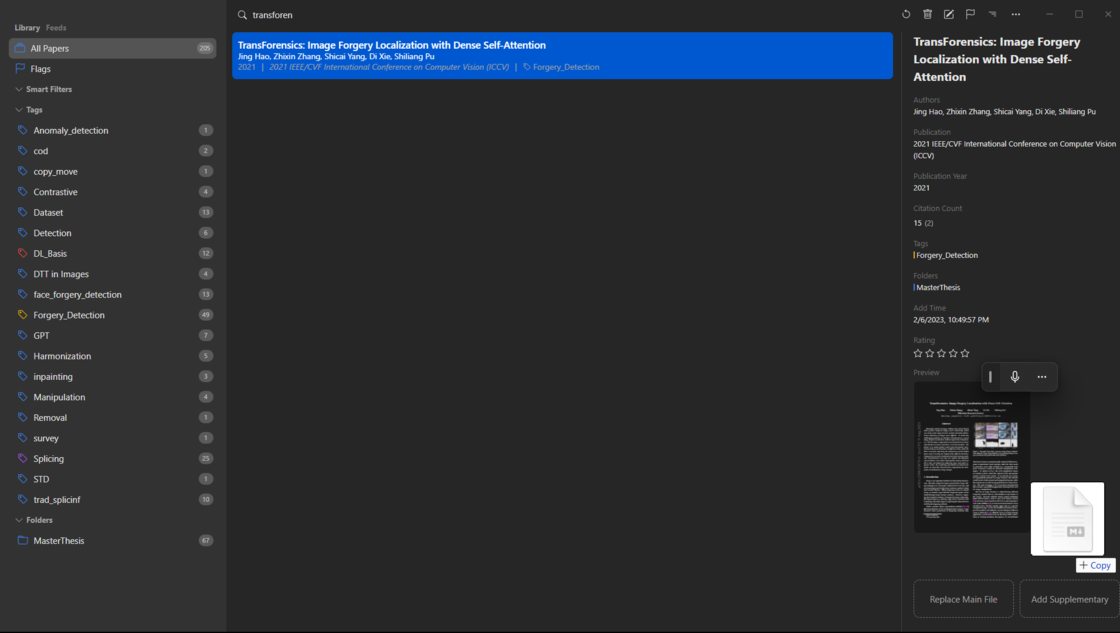
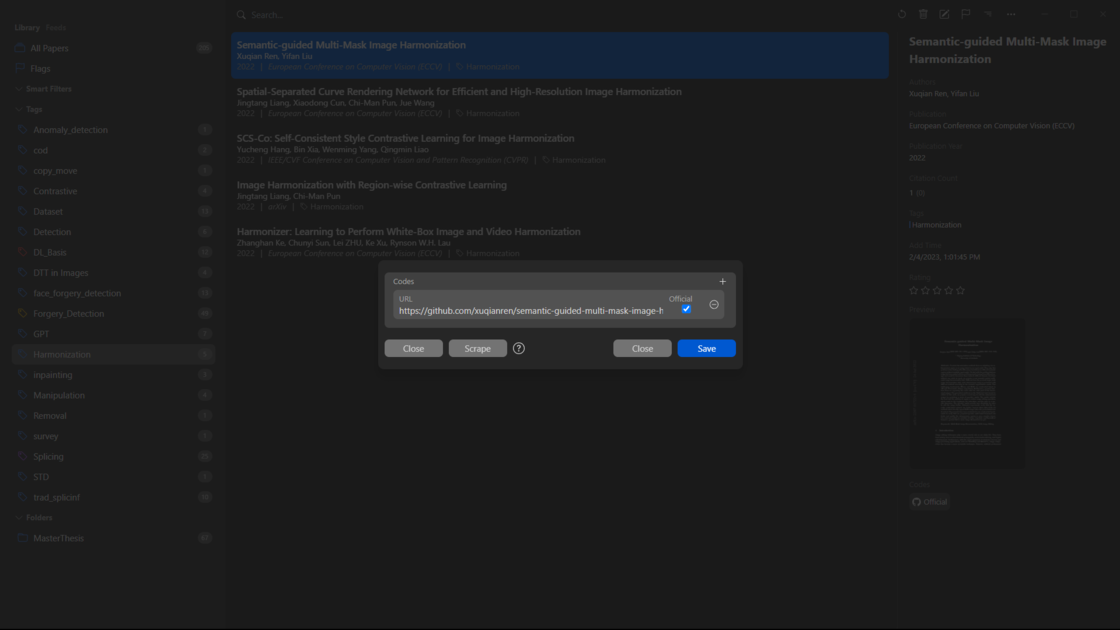
This is the homepage of Paperlib, featuring a straightforward interface. On the left, it covers your own repository and subscribed repositories, with papers categorized based on different tags or folders. In the middle, paper information is displayed, including authors, publication year, journal or conference, and title details. The top search bar facilitates quick paper retrieval. On the right sidebar, detailed paper information is provided; I can rate papers, add corresponding code sources (usually automatically fetched by Paperlib), or modify PDF files retrieved by Paperlib. Right-clicking on a paper allows for data editing, adding flags, and more. In the upper-right corner, I can adjust the corresponding preview view, choosing between List, Table, or other formats, and there are shortcuts for quick operations on papers like deletion, modification, and adding flags.
Adding papers in Paperlib offers multiple options:
- You can directly drag your PDF files into Paperlib’s main view, and Paperlib will automatically configure the paper with the corresponding information based on your custom metadata extractor. This method is less used by me due to potential issues with PDF parsing.
- Paperlib provides a browser extension, allowing you to click on the Paperlib icon while browsing papers, which instantly adds the corresponding paper to the document management tool. The extension is minimalist, just an icon; once clicked, it automatically adds the paper. This method works exceptionally well on arXiv’s website.
- Browser extensions may encounter issues with some paper websites, such as Science Direct from Elsevier’s journal database. Using the second method might fail in such cases. However, you can directly click “Add to Paperlib” in Google Scholar, which is currently my most frequently used method. It never fails and, coupled with Google Scholar’s browser extension, allows you to add papers from any paper page.
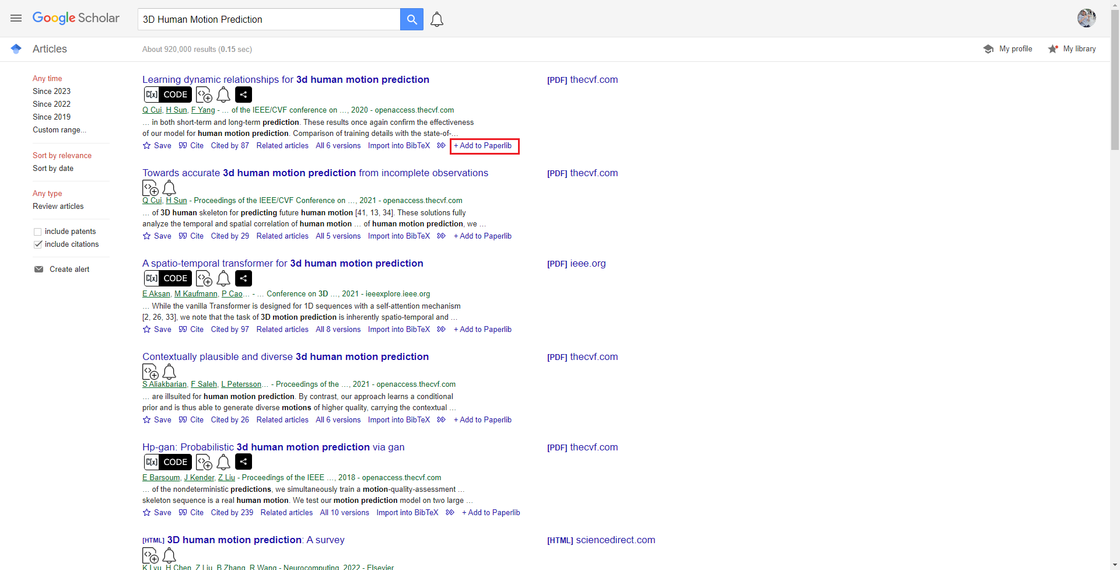
If the added paper cannot be fetched for its corresponding PDF file, you can simply drag the PDF file into Paperlib.
Preview and Reading
In Paperlib, it doesn’t provide a built-in reader but relies on existing PDF reader software on your computer. You can customize which application to open the file with after clicking, then read and annotate the PDF in the corresponding software. You can drag your annotations or reading notes written in other software into Paperlib, and they will be automatically saved. Similar to dragging PDF files as mentioned earlier, on the right side of the replace file entry, is one way to add our notes to the paper.
However, if you just want a quick preview of the paper, you can press the space bar to open the PDF file for quick preview.
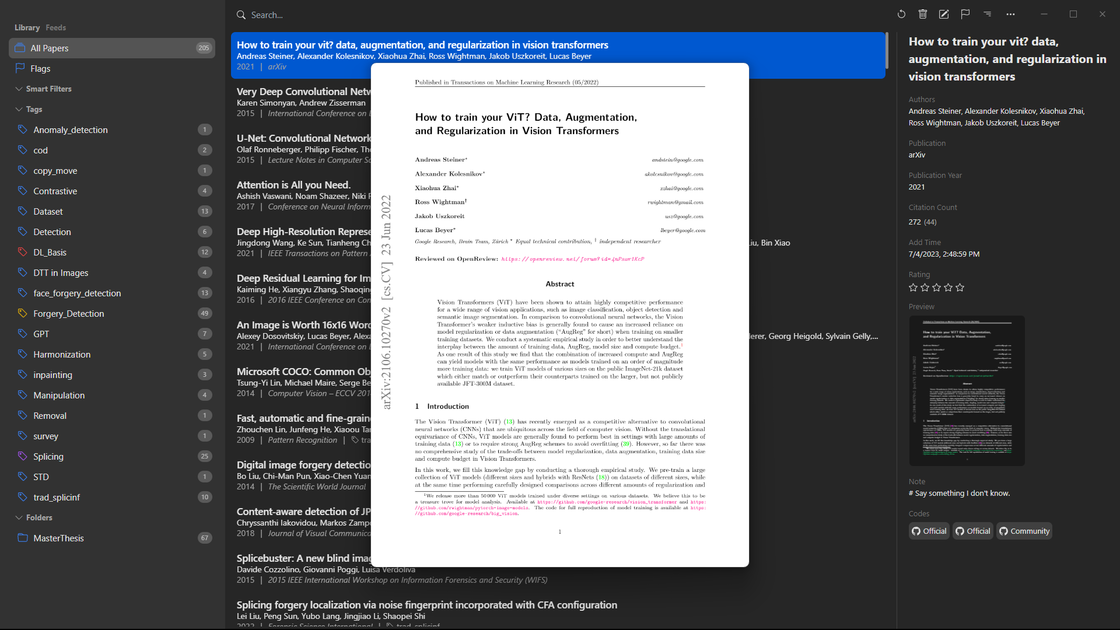
Space or switch to the Table and Reader view.Discovering New Papers
Unlike Mendeley, which sends you weekly emails informing you of papers related to your recent readings, or the built-in recommendation system in ReadCube Papers, Paperlib relies entirely on user customization. It brings us a subscription reader, which means we can freely subscribe to papers relevant to our research topics from different journals or arXiv. Here’s a simple example of some subscriptions I have:
For example, this feed link: https://export.arxiv.org/api/query?search_query=cat:cs.CV+……
https://export.arxiv.org/api/query?search_query
=cat:cs.CV+AND+abs:splicing+AND+abs:image+AND+abs:localization&start=0
&max_results=30&sortBy=submittedDate&sortOrder=descending
As you can see in this link, we’ve customized certain parameters in the search_query. Firstly, cat:cs.CV signifies that we’re specifying the Subject Category of papers on arXiv to be in the field of Computer Vision under Computer Science. Additionally, we can see that more query variables are added later on to control the search, including options like abs, sortBy, and so on.
abs represents the abstract; I want the abstracts of my arXiv papers to include this keyword. If there are multiple keywords, we use AND to connect them. Finally, I want to limit my query results to 30 items, and the sorting of results must be based on the submission date, meaning arXiv will provide the latest papers that fit your query constraints.
Here, I also provide relevant information on how to customize your own feed on arXiv:
arXiv User Manual
search query: https://info.arxiv.org/help/api/user-manual.html#search_query_and_id_list
Appendices: https://info.arxiv.org/help/api/user-manual.html#5-appendices
Subject: https://arxiv.org/category_taxonomy
In addition to subscribing to papers on arXiv, we can also subscribe to papers from journals. The subscription links for journals are usually provided on their official websites. For example, here, I’ve subscribed to papers from journals like ACM Transactions on Graphics (TOG), International Journal of Computer Vision (IJCV), IEEE Transactions on Image Processing (TIP), IEEE Transactions on Multimedia (TMM), Journal of Machine Learning Research (JMLR), IEEE Transactions on Information Forensics and Security (TIFS), and more.
Moreover, within your feeds, you can use search again to find literature that meets your needs.
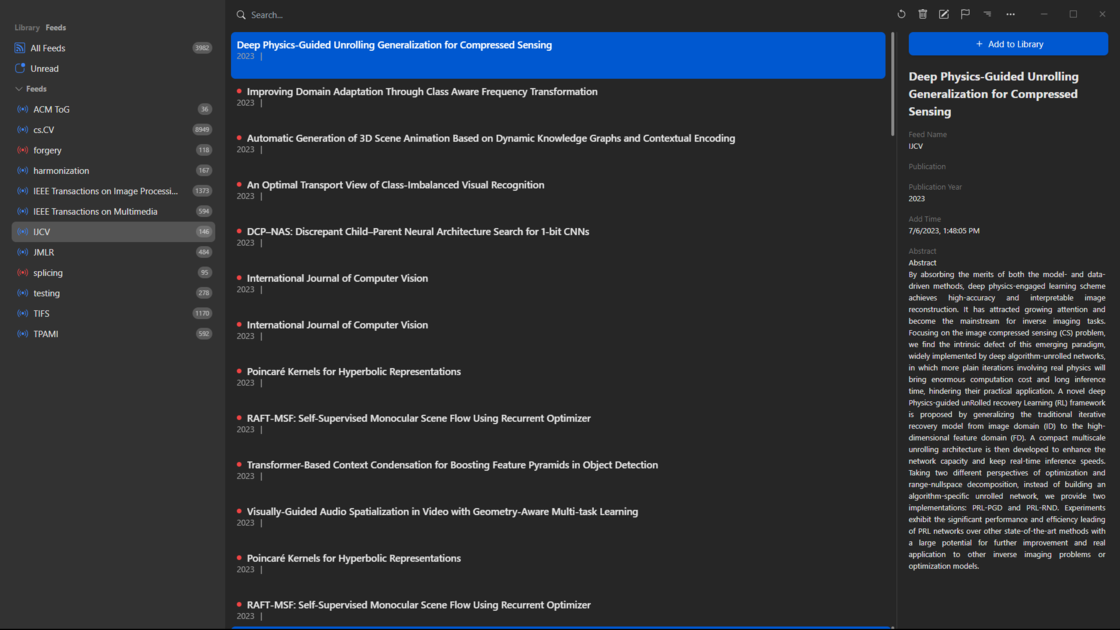
Most journals provide corresponding subscription sources, allowing users to subscribe to different journals based on their needs.
Multi-Platform Sync
For syncing application data, the author provides a tutorial on using MongoDB. By following the tutorial, you can synchronize your paper data across multiple desktop devices, including tag information, folder information, paper details, and your configuration settings.
However, for syncing PDF files, I use Jianguoyun (Nutstore) because it supports multiple platforms, including Linux. Paperlib also offers WebDAV functionality for syncing files between different devices.
Based on my current usage (over 200 papers), Nutstore is sufficient for syncing PDF files across multiple platforms. However, as the number of papers increases, storage space may become limited by Nutstore’s restrictions. Therefore, I am considering using other cloud services to achieve multi-platform synchronization.
Information and Citation
I really appreciate the quick copy-and-paste plugin provided by Paperlib. Since I use LaTeX for writing papers, it’s convenient to place papers into the references. For users writing papers in Microsoft Word, the corresponding extension is currently in beta testing.
Simply click
CMD/CTRL+SHIFT+I, search and select a paper, then pressEnterorSHIFT + Enterto copy BibTeX or BibTeX keys. You can link the plugin to a group, where all your copied papers will be stored. After finishing writing, you can copy all BibTeX strings from this group at once.An ideal writing workflow is: 1) Link the plugin to a group, 2) Continuously search and copy BibTeX keys into your LaTeX file during the writing process, 3) Upon completion of writing, open the plugin and copy all BibTeX strings into the
.bibfile.
Paperlib enriches paper information by providing an entry to add GitHub projects. Additionally, Paperlib automatically searches for corresponding GitHub projects to match the papers.
VS Others
Apart from Paperlib, the document management tools I’ve used include EndNote, Mendeley, ReadCube Papers, and ReadPaper. My first encounter with the concept of document management was through EndNote. My school had purchased a version of EndNote for student use, and I learned about it through an activity introduced by the school library’s public account. Out of curiosity, I downloaded and used it for a while. Until I wrote my undergraduate thesis, I only had a few papers in EndNote. So, my usage wasn’t extensive, and I always felt EndNote had a certain learning curve; it had too many features, and I didn’t quite know where to start.
Later on, I discovered Mendeley, which accompanied me throughout my undergraduate thesis to the first year of graduate school. I even made a video sharing my experience with Mendeley. At that time, Mendeley was fully cross-platform, and I could check my papers anytime on my phone. The desktop client used an application development design rather than the web form used by Manager now.
As Mendeley abandoned its previous desktop version, I coincidentally found ReadCube Papers and promptly switched from Mendeley. ReadCube Papers is still one of my favorite software tools. I subscribed to it for a year, during which my usage frequency was quite high, and the experience was excellent. When the one-year subscription expired, I hesitated to renew it. By that time, my credit card had been charged, but I discovered ReadPaper. Since I was also facing graduation, I considered canceling the subscription. ReadCube Papers was quite user-friendly; I sent them an email, and they promptly refunded the money.
Thus, I started using ReadPaper again. ReadPaper excels in PDF annotation and note-taking functions, but it doesn’t seem to help me manage papers; it’s more like a tool for reading papers. However, there are better options for reading tools. Until one day, I saw a friend had starred this project on GitHub Feeds. I downloaded and installed it, and it turned out to be the tool I was looking for.
Below, I will briefly introduce the characteristics of the previous tools. Since I didn’t extensively use EndNote, I won’t provide specific comments on it for now.
Mendeley
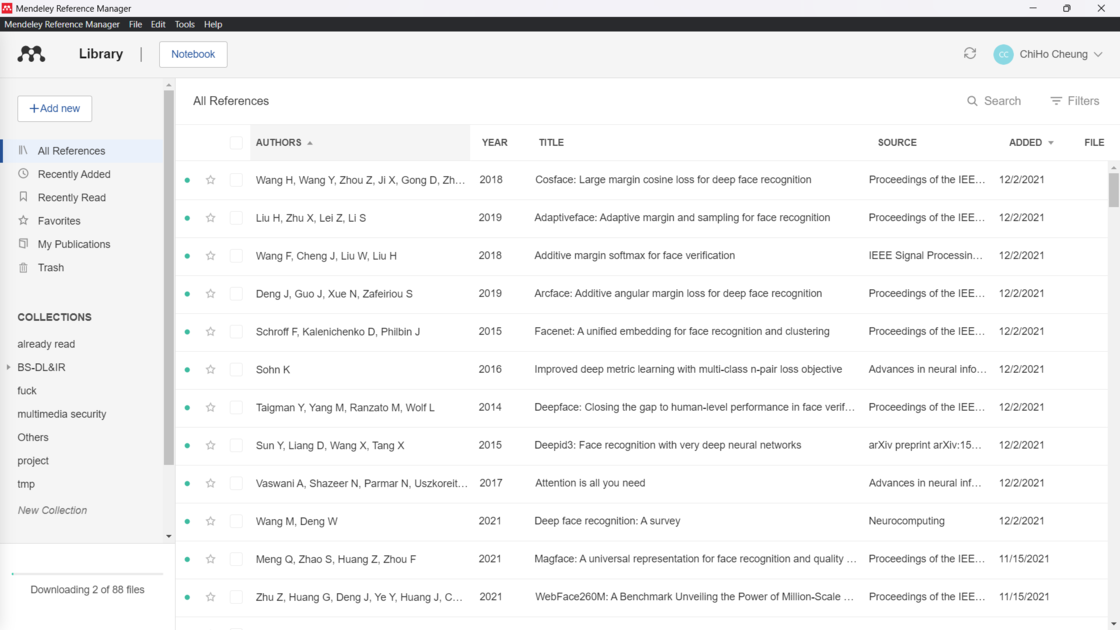
To be honest, my usage of Mendeley was quite some time ago, so my impressions of it may still reflect the Mendeley from two or three years ago. Undeniably, it gave me some impressive experiences. However, as tools that better suited my usage habits emerged, I started to feel somewhat dissatisfied with Mendeley. Most of these dissatisfactions stemmed from the organization and management of documents often lagging behind, giving me a sense of inadequacy. Additionally, while it was possible to drag PDF files into the software interface to automatically add papers, it often required the files to be appropriately named, and they needed to be English-language journal articles to have good results.
- Prior to the update, Mendeley Desktop was supported on all platforms. After the update, it became Mendeley Reference Manager for Desktop. Although it’s an application, the user experience is not much different from the web version, giving me the feeling that it’s like using Mendeley’s built-in browser. Currently, it is only supported on the three major desktop platforms.
- Like all document management tools, Mendeley provides browser plugins and Word plugins to help you add papers and write papers. Mendeley itself also offers paper synchronization and can extract corresponding paper data from PDF files, such as journals, authors, and publication years.
- As mentioned earlier, even on the desktop, there is no difference from the web version. Upon opening, it prompts you to log in to Elsevier. If the web version is affected, the desktop version becomes completely unusable. The downside of being web-based is that the tool doesn’t feel like a tool; various processes become somewhat laggy.
In conclusion, while Mendeley provided me with some stunning experiences, as my requirements evolved, I found that it didn’t quite keep up. The lag in organization and management and the limitations in adding papers were particularly frustrating.
ReadCube Papers
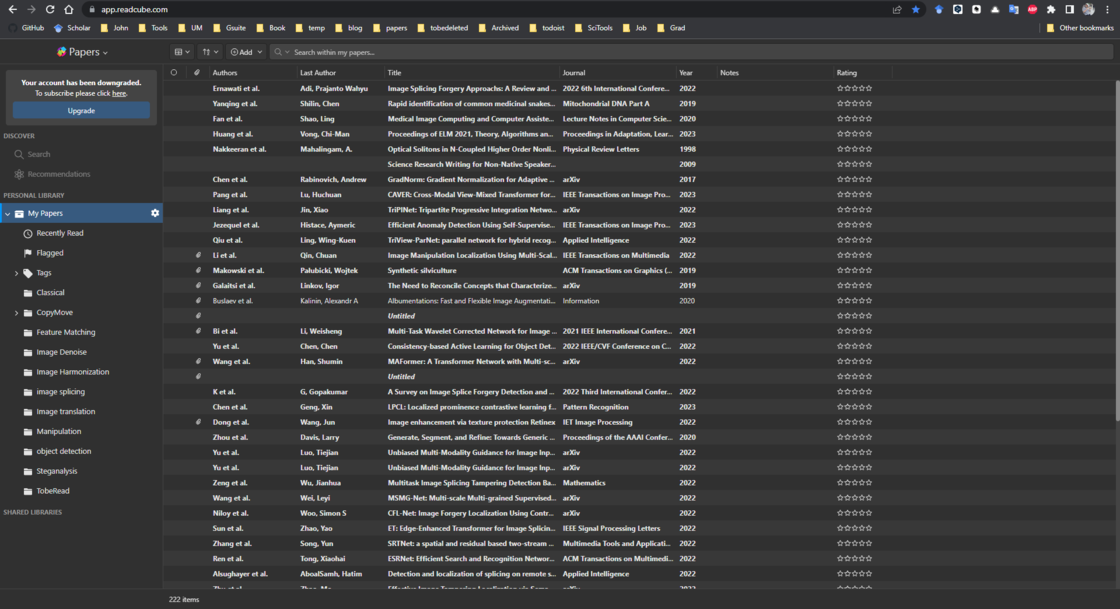
This software remains my favorite. Even Paperlib’s interface is quite similar to it, as is the case with most document management tools, usually following a similar layout.
- Full Platform Support: (Android, iOS, iPadOS, macOS, Windows, Web, SmartCite (Word, Google Docs), Browser Extension (Chrome, Firefox, Safari, Edge))
- Recommendation Mechanism: Papers recommends papers related to your library based on its built-in recommendation algorithm. However, the drawback is that most recommendations are for journal papers, with fewer from arXiv or various conference papers.
- Automatic Download: In Papers, you can configure your school library’s proxy information. If you’re on campus, it automatically downloads PDF files of papers from databases your school has purchased, such as IEEE Xplore or the ACM Digital Library.
- Automatic Cloud Sync Across All Platforms: With Papers, you don’t need to worry about limited storage capacity like with Zotero, Paperlib, or other tools, or about connecting to cloud services like Nutstore or Dropbox. Papers provides unlimited cloud storage for you.
- Simple Note-Taking Functionality: While the PDF annotation feature is not as good as desired, this is one reason I stopped using it extensively. Papers offers built-in paper reading with basic PDF annotation features like highlighting, underlining, strikethrough, adding notes, and handwriting. However, the handwriting experience in Papers is quite poor, even worse than in ReadPaper. One reason might be that Papers doesn’t extract full text from papers like ReadPaper does, processing the text at a different level, making it difficult to select text for highlighting or underlining. However, Papers can extract references and display them in the sidebar without needing to scroll to the bottom.
- Built-In Search: While not essential for me in a document management tool, the built-in search in Papers provides detailed data similar to Google Scholar. However, I usually don’t search for papers directly within a document management tool.
ReadPaper
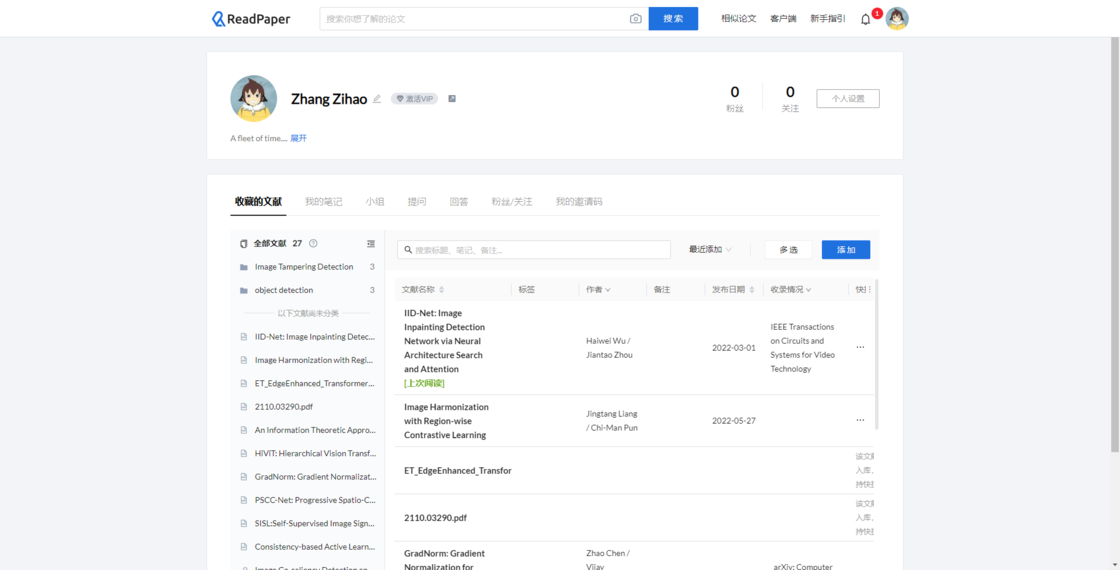
ReadPaper emphasizes community culture. Initially, features like full-text translation and similar papers require sharing with other new users to unlock. However, I found the document management interface displayed too little information, and the layout of many details could be presented in a more compact manner.
Community Interaction: Users can add friends, join different study groups, and read papers together with friends. The community aspect is strong, allowing users to find their papers in academic communities, read together with friends, ask questions directly, and wait for answers from other users.
Platform Support: Available on Windows, macOS, and iPad platforms.
Built-In Reader: Extracts information from papers, allowing for quick paper translations through different translation services. Charts are automatically extracted, references can be easily located, and handwritten notes (only on iPad) and keyboard text notes can be added. Users can also modify color modes, such as black background with white text.
ReadPaper Mini Program: Provides the latest arXiv subscriptions. Users can select subscriptions from a list of fields. The mini program displays paper titles, authors, and abstracts but does not provide links to the original texts.
Document Management: Tables adjust row height automatically based on content. Features include folders, nested folders, tags, etc.
Paperlib’s Drawbacks
There might be some users who wish to have features like PDF annotation and editing, or feel that the current support for conferences or journals is not extensive enough, among other needs. However, for me, these shortcomings don’t quite define Paperlib as a literature management tool tailored for the computer science discipline. Here are the drawbacks I’ve observed while using Paperlib:
Lack of Multi-Platform Support: For instance, there’s no way to access my papers on my smartphone. The author mentioned not having an Apple Developer account, and being the sole developer and maintainer, facing some limitations in terms of energy and resources due to academic commitments.
Absence of Recommendation Mechanism: As I mentioned earlier with ReadCube Papers, I really liked its recommendation feature. However, in Paperlib, this could potentially be addressed quite well using the RSS subscriptions in the Feeds section. A better approach might involve the software using recommendation algorithms based on information such as paper titles, abstracts, and authors from subscribed feeds to offer rough paper recommendations.
Of course, being an open-source software, “free” not only means free of charge but also implies that we can freely modify it to suit our preferences.
Whether you prefer ReadCube Papers, ReadPaper, or Paperlib, they are all quite outstanding tools. As I mentioned at the beginning, it often comes down to personal preferences or even just the initial impression. Regardless, everyone is welcome to recommend the tools they are currently using.